OmniActions:利用LLM预测数字动作以响应现实世界的多模态感官输入
论文总结
摘要
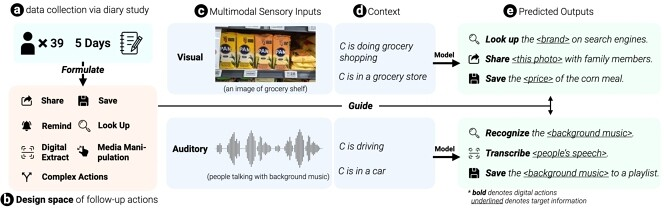
本研究通过日记研究法收集用户对日常生活中的多模态信息(如视觉、听觉)的后续行动数据,以了解人们可能采取的行动。研究人员构建了一个名为OmniActions的系统,该系统利用大型语言模型(LLMs)预测用户在遇到新信息时可能执行的操作,并针对这些信息提供结构化的文本描述。研究通过三种LLM技术(意图分类、基于链式思考的内上下文学习和细粒度微调)进行评估,结果显示使用CoT提示的内上下文学习方法在预测目标信息和后续行动方面表现出较高的准确率。此外,研究人员还开发了一个移动原型系统,并通过用户反馈了解了用户对系统预测及其错误的看法。研究结果为未来增强现实(AR)场景中的交互设计提供了指导。
问题发现
人们在日常生活中会遇到各种多模态信息(如图像、文本、音频等),他们可能会有多种后续行动,但如何便捷地针对这些信息采取行动存在挑战。传统的系统往往只能处理单一类型的信息或操作,不能满足用户对复杂信息的多样化需求。
解决方案
为解决这个问题,研究者进行了一项五天的日记研究,鼓励参与者记录他们在遇到新信息时希望执行的操作。通过收集和分析这些数据,构建了一个涵盖多种后续行动的设计空间。接着,设计了OmniActions系统,该系统能够接收多模态输入(如图像、文本、音频),使用现有的模型将其转换为结构化的文本,并利用LLMs预测目标信息和可能的后续行动。
结果
研究结果表明,通过内上下文学习与CoT提示的方法,OmniActions在预测目标信息和后续行动时表现出较高的准确率。特别是在预测前三个一般性行动时,准确率达到94%。用户反馈表明系统具有潜力,并提供了改进设计和用户体验的建议。这为未来AR平台中理解用户信息需求和提供相关交互指明了方向。
举一反三
Q1:用户在日常生活中如何与多模态信息交互?
A1:用户通过各种方式与多模态信息进行交互,如拍照、录像、聆听环境声音等,并基于这些信息执行后续操作,如分享、搜索或保存。
Q2: OmniActions系统是如何帮助用户减少获取和处理现实世界信息时的摩擦?
A2:OmniActions通过理解用户的多元感官输入(如视觉、听觉),转化为结构化的文本,并利用大型语言模型预测用户可能采取的后续行动,从而减少用户在识别和响应环境信息上的操作步骤。
Q3:研究团队如何构建并验证OmniActions的设计空间?
A3:研究团队首先通过工作坊理解日常生活中人们遇到的多模态触发点和相关行为。接着进行日记研究,收集参与者在遇到新信息时希望采取行动的数据,这些数据被用来创建设计空间,并进一步指导OmniActions原型系统的开发。
原文地址:https://dl.acm.org/doi/10.1145/3613904.3642068
内容由MiX Copilot生成