使用大型语言模型协助从头开始编写类似维基百科的文章
论文总结
研究机构
- 斯坦福大学(Stanford University)
摘要
本研究关注如何利用大型语言模型(LLMs)从头开始撰写具有广度和深度的维基百科风格的文章。这一尚未充分探索的问题在写作前阶段提出了新的挑战,包括如何研究主题并准备大纲,以便有组织地进行写作。研究者提出了一种名为STORM的方法,它通过模拟对话中的多视角问题来研究主题,并使用特定视角来引导提问。STORM通过创建可以逐节扩展至全文的大纲来生成完整的维基百科式文章。
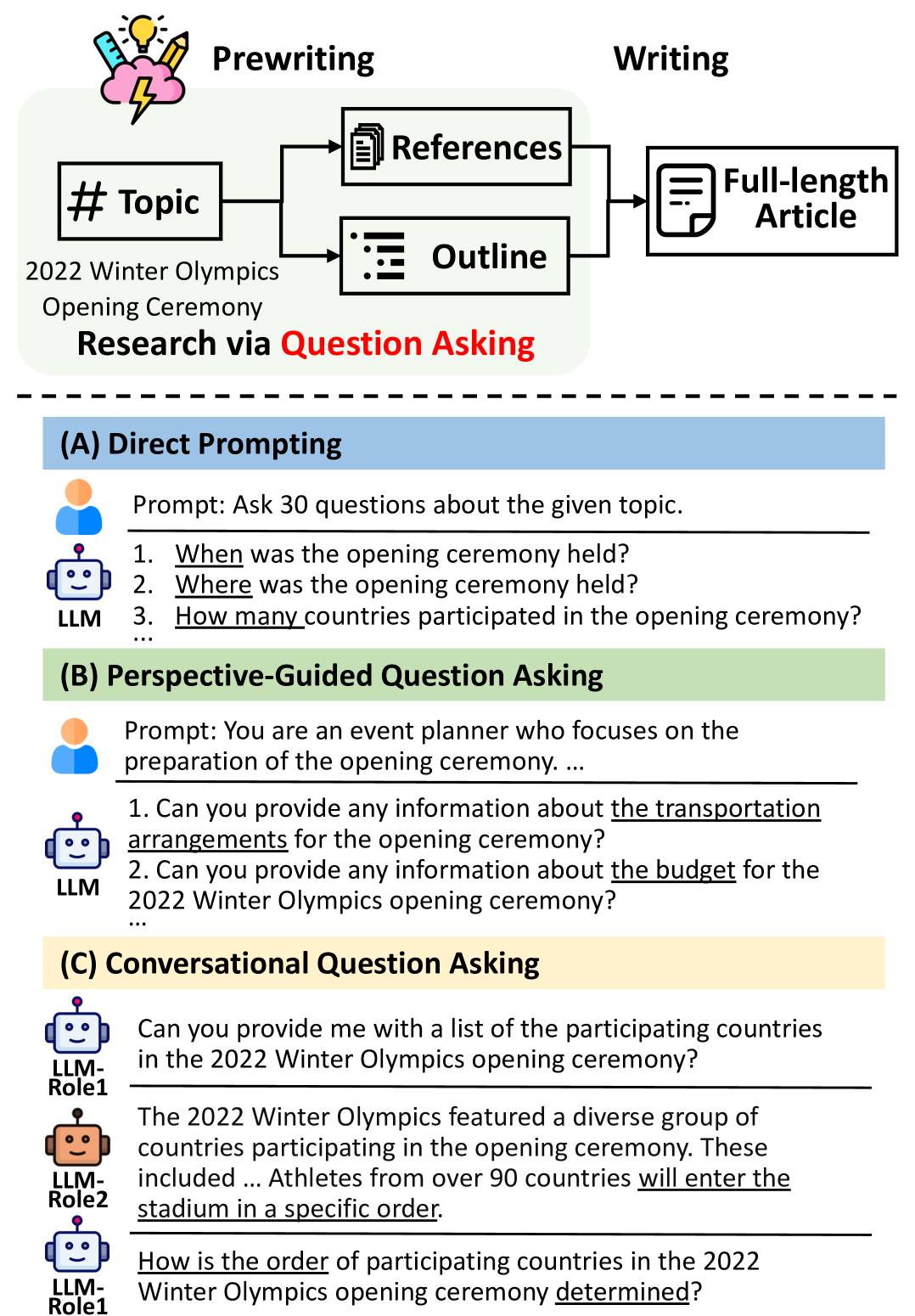
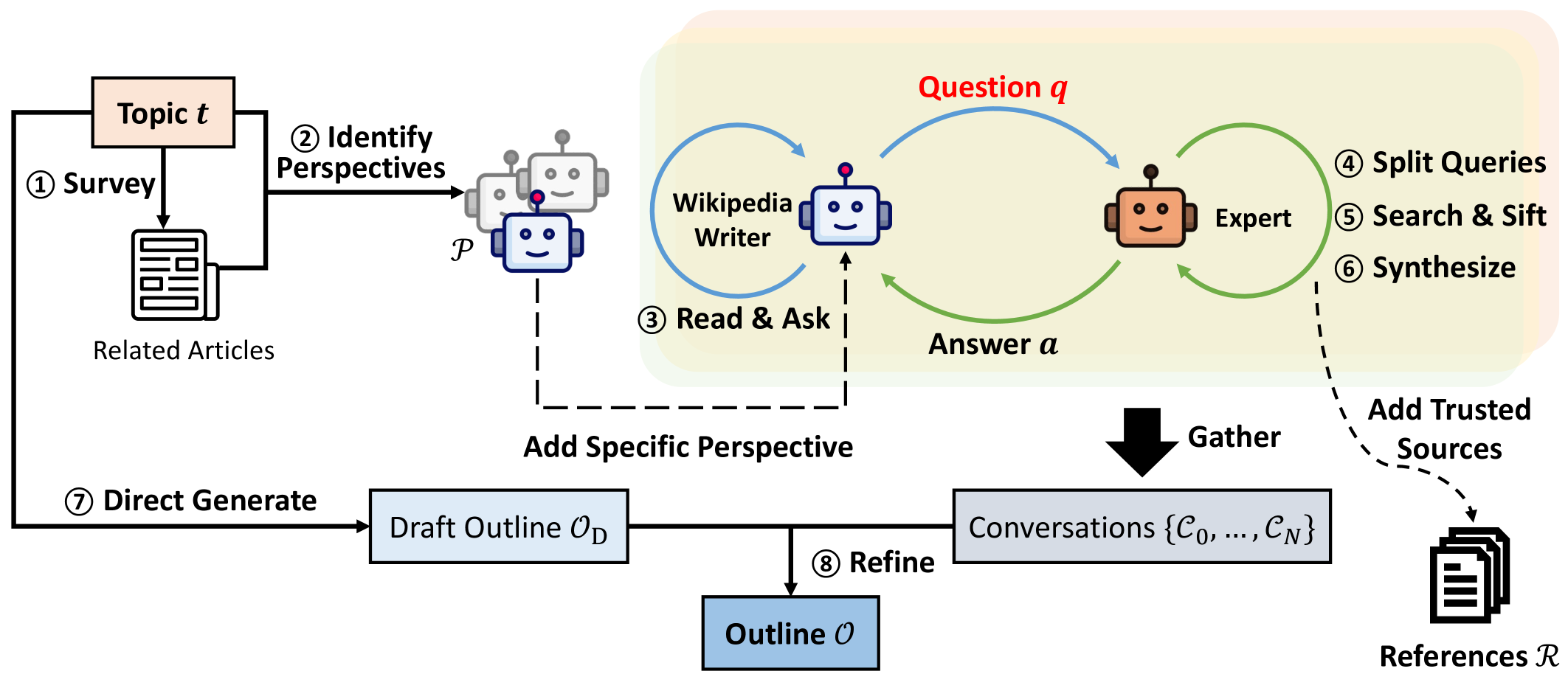
问题发现
- 如何有效利用LLMs在没有明确大纲或参考文档的情况下撰写长篇内容。
- 在写作前阶段(如收集和整理相关信息)的挑战,包括研究、准备大纲以及保持内容的权威性和连贯性。
解决方案
- STORM采用多阶段方法:首先通过检索相似主题的维基百科文章来发现不同的视角,并使用这些视角控制提问过程。
- 通过模拟专家与模型对话,模型能更新对主题的理解并提出更深入的问题。
- 利用LLMs生成可信来源的答案,以回答在查询过程中提出的问题。
结果
- 经过自动和人类评估,STORM方法在大纲质量方面优于基于大纲的检索增强生成(RAG)基线。
- 通过与 Wikipedia 编辑的人工评价,STORM展现出其生成的文章具有较高的连贯性、相关性和可验证性。
- 编辑反馈显示,STORM生成的文章比基线提供了更多背景信息,并且深度更佳。
结论
STORM通过自动化预写作阶段,利用LLMs有效研究主题并创建全面的大纲,为撰写维基百科风格文章提供了一种可行的方法。该方法在某些方面超越了现有的基于检索的生成模型,并为未来长篇内容生成提供了新的思路。
举一反三
Q1:STORM在撰写文章时如何处理信息的多样性和来源?
A1:STORM通过发现不同视角,例如通过检索类似主题的维基百科文章,并使用这些视角控制提问过程。它模拟与专家的对话以获取更深入的问题答案,并利用可信赖的互联网资源作为基础来生成内容。
Q2:如何评估STORM在撰写文章时的预写阶段?
A2:STORM的预写阶段通过创建能够扩展为多级标题列表的轮廓来进行评估。使用软标题召回率和实体头文件回忆率来衡量其相对于人类写作的全面性。此外,还邀请了经验丰富的维基百科编辑进行专家评价。
Q3:如何解决STORM在生成文章时可能存在的问题,比如偏见转移和信息准确性?
A3:为了解决这些问题,可以继续改进模型训练数据的质量,确保使用中立且可靠的来源。同时,对模型生成的内容进行人工审核和校正,以减少错误和不准确的信息,并避免偏见的传递。
原文地址:https://arxiv.org/html/2402.14207v2
内容由MiX Copilot基于大语言模型生成,有可能存在错误的风险。